


Meta MobileLLM-R1 : Best Small Reasoning LLMs
How to use MobileLLM-R1 for free?

Meta just dropped a new line of models under their MobileLLM family, called MobileLLM-R1. And unlike the usual flood of chatbots, these are reasoning-focused models. No fluff, no chit-chat.
https://medium.com/media/855a4ca11fa148b92c7891445263f4b3/href
They’re trained specifically for math, coding (Python, C++), and scientific problems.
Model Context Protocol: Advanced AI Agents for Beginners (Generative AI books)
The lineup is split into two buckets:
- Base models: MobileLLM-R1–140M-base, 360M-base, 950M-base
- Final models: MobileLLM-R1–140M, 360M, 950M
The base ones stick to 4k context length. The final ones stretch to 32k, which is already a big step for handling longer reasoning chains.
Why It Matters
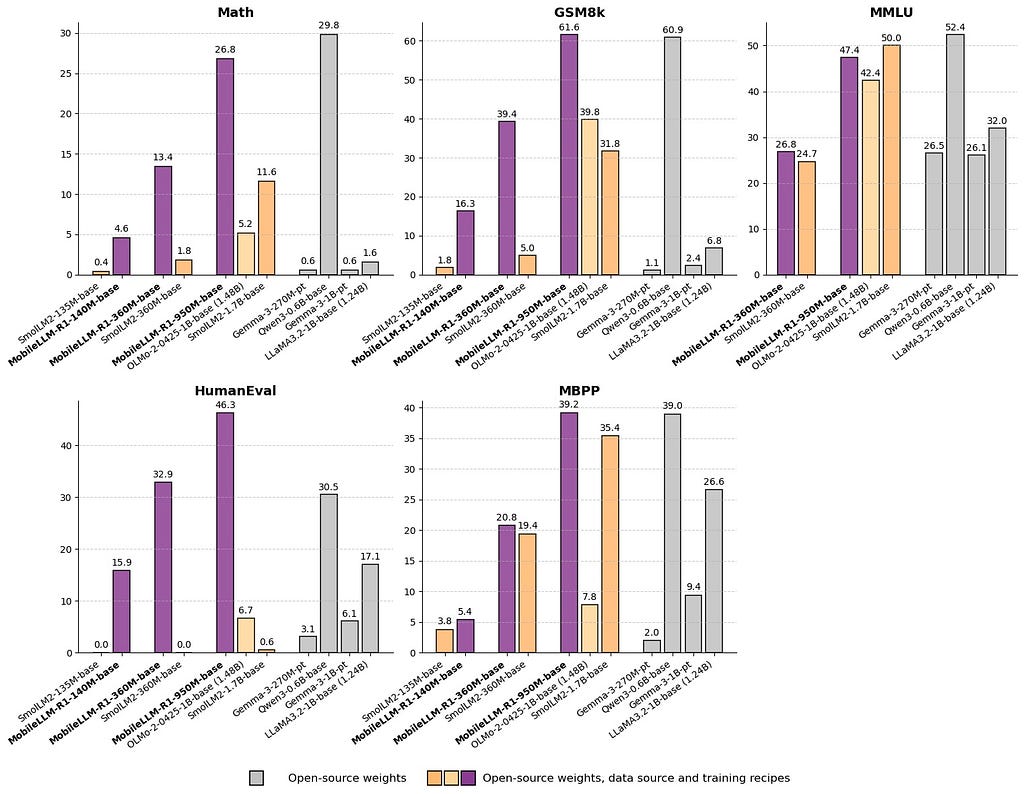
The surprising bit isn’t just that these models are compact. It’s how efficient they are.
The largest, MobileLLM-R1 950M, was trained on fewer than 5T tokens (only ~2T high-quality pretrain tokens). Yet, it beats or matches Qwen3 0.6B, which chewed through 36T tokens.
Benchmarks back this up:
- On MATH, it’s about 5× more accurate than Olmo 1.24B and 2× better than SmolLM2 1.7B.
- On coding tasks, it’s not even close. The 950M model sets a new state-of-the-art for open-source models in its size range.
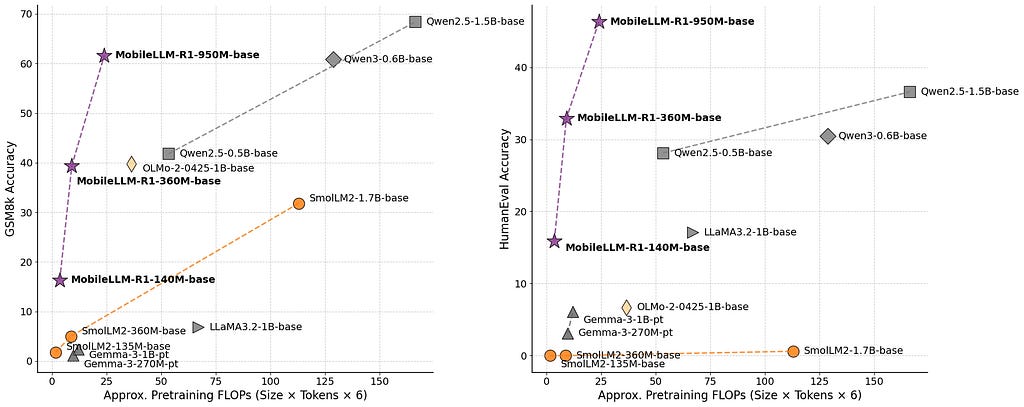
In short: smaller, trained on less, but delivering more.

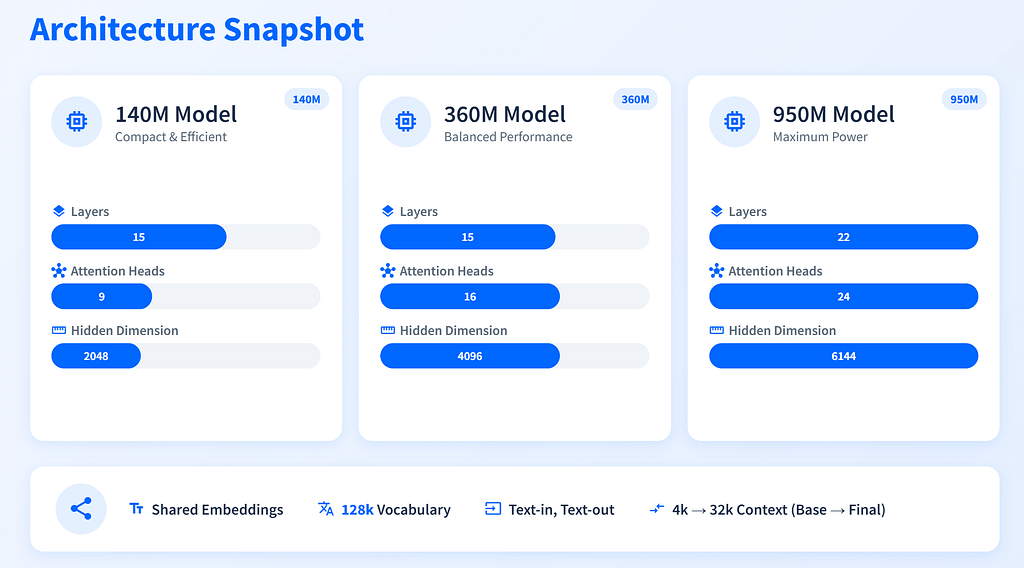
Architecture Snapshot
Here’s a quick glance at the specs:
- 140M model: 15 layers, 9 heads, hidden dim 2048
- 360M model: 15 layers, 16 heads, hidden dim 4096
- 950M model: 22 layers, 24 heads, hidden dim 6144
All of them use shared embeddings, a 128k vocabulary, and stick to text-in, text-out.
Openness Done Right

Meta isn’t just throwing binaries over the wall. They’re publishing:
- Full training recipes
- All data sources
That’s rare and important. It makes the work reproducible and lets other researchers actually build on top of it.
The model weights are open-sourced and can be accessed below
facebook/MobileLLM-R1-950M · Hugging Face
Codes
from transformers import AutoModelForCausalLM, AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("facebook/MobileLLM-R1-950M")
model = AutoModelForCausalLM.from_pretrained("facebook/MobileLLM-R1-950M")
from transformers import pipeline
import torch
model_id = "facebook/MobileLLM-R1-950M"
pipe = pipeline(
"text-generation",
model=model_id,
torch_dtype="auto",
device_map="auto",
)
# Math problem / default scenario
messages = [
{
"role": "system",
"content": "Please reason step by step, and put your final answer within \boxed{}."
},
{"role": "user", "content": "Compute: $1-2+3-4+5- \dots +99-100$."},
]
# C++ coding scenario
messages = [
{
"role": "system",
"content": (
"nYou are a helpful and harmless assistant. You should think step-by-step before responding to the instruction below.nn"
"Please use c++ programming language only.n"
"You must use ```cpp for just the final solution code block with the following format:n"
"```cppn# Your code heren```n"
)
},
{"role": "user", "content": "Write a C++ program that prints 'Hello, World!'."},
]
# Python coding scenario
messages = [
{
"role": "system",
"content": (
"nYou are a helpful and harmless assistant. You should think step-by-step before responding to the instruction below.nn"
"Please use python programming language only.n"
"You must use ```python for just the final solution code block with the following format:n"
"```pythonn# Your code heren```n"
)
},
{"role": "user", "content": "Write a Python function that returns the square of a number."},
]
outputs = pipe(
messages,
max_new_tokens=8192,
)
print(outputs[0]["generated_text"][-1])
Why You Should Care
The narrative around open-source models often feels like: “train huge, spend billions, and maybe compete.” MobileLLM-R1 quietly flips that. It shows you can squeeze surprising reasoning skills into sub-1B parameter models with efficient training.
For anyone working in math-heavy or code-heavy applications, these models look like the sweet spot: lightweight enough to run on smaller setups, but sharp enough to hold their ground against much larger peers.
Meta MobileLLM-R1 : Best Small Reasoning LLMs was originally published in Data Science in Your Pocket on Medium, where people are continuing the conversation by highlighting and responding to this story.



