



GLM 4.6 : The best Coding LLM, beats Claude 4.5 Sonnet, Kimi
How to use GLM 4.6 for free?
z.ai has rolled out GLM-4.6, the direct successor to GLM-4.5. On paper, it looks like an incremental upgrade, longer context, better coding, better reasoning, but if you dig into benchmarks and real-world tests, the picture gets more interesting.
https://medium.com/media/73db0a38c28b3d1c03d78fd553af4335/href
Context Window: 200K vs 128K
The most obvious upgrade is the jump from 128K to 200K tokens.
For non-specialists, “context window” means how much the model can keep in memory while reasoning. Imagine trying to debug a 50K-line project, or process a long chain of user interactions: with 128K tokens, you’re capped earlier. 200K gives breathing room.
That extra space doesn’t just mean “more text in.” It makes multi-step workflows like planning, executing, and revising across multiple tool calls, more reliable.
For agentic systems that depend on carrying state across dozens of steps, this upgrade matters more than benchmark scores.
Coding Ability: Benchmarks

GLM-4.6 is explicitly tuned for coding, and the gains show up in both benchmarks and practice.
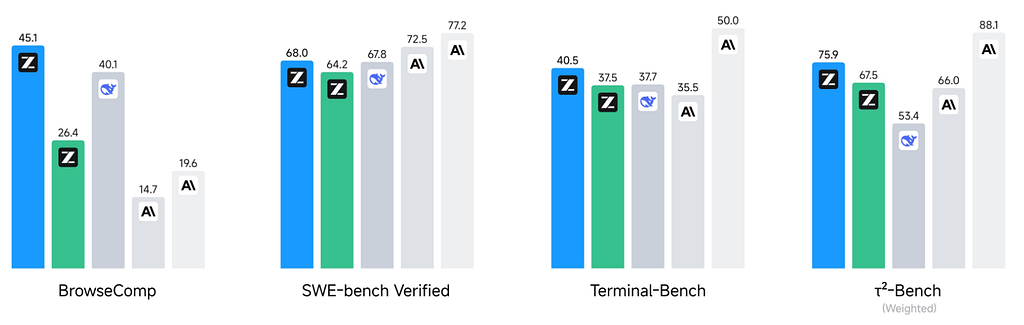
- On LiveCodeBench v6, it scores 82.8 vs GLM-4.5’s 63.3, a big jump. Claude Sonnet 4 leads at 84.5, but the gap is marginal.
- On SWE-bench Verified, it clocks 68.0, again ahead of GLM-4.5 (64.2) and near Claude Sonnet 4 (67.8). Claude Sonnet 4.5 still tops out at 77.2.
- On BrowseComp, GLM-4.6 almost doubles GLM-4.5’s performance (45.1 vs 26.4).
The pattern: GLM-4.6 consistently beats GLM-4.5 across code-related tasks, matches Claude Sonnet 4 in places, but Claude Sonnet 4.5 is still the gold standard for hard coding problems.
Benchmarks aside, what matters is real-world usage in coding agents. GLM-4.6 integrates with Claude Code, Roo Code, Cline, and Kilo Code. Developers testing it report noticeably better front-end output, the kind of polish that usually requires manual cleanup. That suggests its code generation isn’t just syntactically correct but also more aligned with human expectations of design.
Reasoning and Tool Use
Reasoning performance has improved as well. On AIME 25 (math-heavy reasoning), GLM-4.6 scores 93.9 vs GLM-4.5’s 85.4. With tool use enabled, it even climbs to 98.6, which is competitive with Claude Sonnet 4 (87.0) and only slightly behind Claude Sonnet 4.5 (74.3).
This is where GLM-4.6 shows its “agentic” edge. Many LLMs can reason decently, but combining reasoning with active tool use during inference is tricky. GLM-4.6 handles this more naturally, allowing it to chain search, retrieval, or computation tools without wasting context or tokens.
Agent Performance

When dropped into agent frameworks, GLM-4.6 clearly improves over 4.5. In CC-Bench-V1.1, which simulates real-world multi-turn dev tasks inside isolated Docker containers:
- GLM-4.6 vs Claude Sonnet 4 → 48.6% win rate (near parity).
- GLM-4.6 vs GLM-4.5 → Wins 50% of cases, with only 36.5% losses.
- GLM-4.6 vs DeepSeek-V3.1-Terminus → Wins 64.9%, dominates.
These aren’t just one-off problems. Tasks include front-end builds, tool development, data analysis, testing, and algorithm design stuff you’d actually pay a model to do.
What’s notable is that GLM-4.6 is doing this while using ~15% fewer tokens per task than GLM-4.5 (651K vs 762K on average). Against DeepSeek V3.1, it’s far more efficient (651K vs 947K). This efficiency makes it cheaper and faster in real agent deployments.
Writing and Alignment
While not the main focus, GLM-4.6 also improves on refined writing. It aligns closer with human style, performs better in role-playing scenarios, and avoids the robotic flatness sometimes seen in earlier GLM releases. This isn’t trivial: smoother alignment makes a model less frustrating in collaborative coding or research sessions, where tone and readability matter.
Pricing and Access : Cheapter, Better, Faster
z.ai is leaning hard on affordability:
$0.6/million input tokens, $2.2/million output tokens.
GLM Coding Plan starts at $3/month, pitched as “9/10ths of Claude at 1/7th the price.”
Coding Max plan gives triple the usage compared to Claude Max.
Access routes:
- Available now via Z.ai API
- Supported inside major coding agents (Claude Code, Roo, Cline, Kilo).
- Will be open-sourced soon on Hugging Face and ModelScope under MIT.
Weaknesses and Gaps
No model release is perfect, and GLM-4.6 has limits worth noting:
- Claude Sonnet 4.5 still leads in raw coding power. For deep debugging or extremely tricky code reasoning, Claude remains more reliable.
- Latency and efficiency: While GLM-4.6 is more token-efficient than 4.5, it’s not the lightest model. Smaller agents might still prefer highly-optimized models like DeepSeek for cost-sensitive use.
- Ecosystem maturity: While z.ai Coding Plan is cheap, Claude and OpenAI still have stronger third-party integrations and user adoption outside China. That affects community support and tooling.
Why GLM-4.6 Matters
GLM-4.5 proved a single model could unify reasoning, coding, and agent capabilities. It made z.ai one of the few serious Claude competitors. With GLM-4.6, the company isn’t just chasing leaderboards it’s closing gaps in real-world coding and agent workflows.
The benchmarks confirm progress, but the Docker-based CC-Bench tasks highlight something more important: developers can actually build with this. Add to that token efficiency, cheap pricing, and an open-source roadmap, and
GLM-4.6 stands out as one of the most practical coding-first models available today.
GLM 4.6 : The best Coding LLM, beats Claude 4.5 Sonnet, Kimi was originally published in Data Science in Your Pocket on Medium, where people are continuing the conversation by highlighting and responding to this story.



